
Plant teams across the industry are being told to “do something with AI.” The pressure is mounting from boardrooms, suppliers and the industry at large. But here’s the problem: most of that pressure comes with very little grounding in what AI actually is, how it works in the cement industry, or how to tell the difference between a solid technical solution and expensive hype.
While LLMs dominate headlines in the mainstream, suppliers pitch “AI-powered” solutions that promise transformation but rarely explain the mechanism. And in the middle of all this noise, plant engineers are expected to have the knowledge to integrate systems into production environments that have zero tolerance for failure.
Our webinar series sets out to give you the technical foundation to understand AI solutions, how they work and judge if they’re right for you. If you’re a process engineer, optimisation engineer, production manager, or technical director who needs to make real decisions, this is for you.
Below are five key takeaways from our recent webinar. They won’t make you a machine learning engineer, but they will give you the grounding to ask better questions, spot the red flags, and make decisions you can defend.
1. AI and ML are not the same thing
Let’s start with the basics, because the terminology matters more than you think.
Artificial intelligence (AI) is the broad goal: building systems that can reason, make decisions, plan, and understand language. It’s about creating “intelligent” behaviour in machines.
Machine learning (ML) is a method for achieving AI. It’s how you teach computers to perform tasks by learning from data, rather than being explicitly programmed to follow a set of rules.
Here’s the critical part: not all AI uses ML, and not all ML looks like ChatGPT. Large language models like ChatGPT are one specific type of ML, neural networks trained on massive amounts of text data to generate human-like responses. They’re impressive, but they represent a narrow branch of a much wider field.
In cement production, ML is being used in fundamentally different ways. The three core categories you need to understand are:
- Supervised learning: Training models with labelled data to predict outcomes. Example: predicting free lime from fuel throughput and raw meal chemistry.
- Unsupervised learning: Finding patterns in data without predefined labels. Example: identifying distinct operating regimes in your kiln based on process conditions.
- Reinforcement learning: Teaching systems to take actions and learn from feedback. Example: controlling fuel setpoints in real time to optimise for cost, emissions, or throughput.
When a supplier says “AI,” the first question you should ask is: which type of machine learning are you actually using, and why is that the right approach for this problem?
2. Your data is the foundation, not the model
This is the unglamorous truth: no amount of sophisticated modelling overcomes poor data quality. Garbage in, garbage out, as we like to say.
A good model needs a large amount of high-quality data. But in cement, that’s harder to come by than it sounds. Pyroprocess environments are harsh. Sensors fail. Gas analysers run cleaning cycles that produce false readings. Thermocouples drift. Data gets corrupted, goes missing, or just plain lies to you.
Before any model sees your data, it has to be cleaned. For example, when it comes to gas analyser data we remove cleaning cycles to get the true measured values. That means filtering data to remove spurious values and outliers that would confuse the model and applying our domain expertise to select which signals actually matter.
This is not a one-off task. When a model is running in a plant, the live process, chemistry and lab data that is fed into the model is processed in real-time to ensure accurate predictions and recommendations. Data cleaning is foundational work that determines whether your AI implementation succeeds or fails.
Once you have a cleaned dataset, you train a model. The model outputs predictions (like free lime) or recommended setpoint values (like precalciner temperature). When models are deployed on the plant, they need to be monitored and updated regularly as conditions change. An important question to ask a supplier is how often they update or retune their models and is it automatic. Auto-retuning ensures the model adapts to changing plant conditions without manual maintenance but again, it only works if the data foundation is solid.
To ensure your plant is AI ready you should understand if your data is:
- Accessible locally and remotely to all parties, e.g. stored on a cloud historian.
- Connected – Is lab and process data stored in the same place are your advanced process control settings available?
- Recorded – how extensive are your historical records, good accurate models require at least 6 months of consistent data.
3. Understanding how models learn (and fail) makes you a better buyer
Let’s talk about how models actually learn.
When training a model, you split your historical data into two sets: a training set (which the model learns from) and a test set (which you use to evaluate how well the model performs on data it has never seen).
This is critical. A model that performs well on training data means almost nothing. What matters is how it performs on the test set, because that’s the closest proxy you have for how it will behave in production.
Parameters vs. hyperparameters: Parameters are what the model learns from the data (like the slope and intercept of a line in linear regression). Hyperparameters are design choices you make before training begins (like how many layers a neural network has, or how many trees are in a random forest). Both matter, and neither should be a black box.
Evaluation metrics: There are many evaluation metrics you can use to judge how well a model performs. And different metrics are chosen based on the context of the model. MAE (mean absolute error) and MSE (mean squared error) are two common ways to quantify how good a model is. MAE tells you, on average, how far away from the correct value your predictions will be. The lower the error, the better.
Overfitting: If a model is too complex for the data, a model will overfit and struggle to generalise new data, learning the noise in the training data rather than the real underlying relationship. An overfit model looks great on paper and falls apart in the real world.
4. Model complexity is secondary to explainability
More complexity does not automatically mean better performance. In fact, in industrial settings, explainable models often win and are easier to understand and trust.
The spectrum of model types runs from simple (linear regression) to complex (neural networks, transformers). Each has its place, but the question should always be: is this the right level of complexity for the problem and the data we have?
Linear regression is the simplest approach: fitting a straight line (or plane) through your data. It’s interpretable, fast, and works well when relationships are straightforward. But cement processes are rarely linear. A one ton per hour (tph) increase in coal doesn’t always produce the same temperature change, because the effect depends on what else is happening in the system.
Ensemble methods like random forests are a powerful middle ground. They combine predictions from many decision trees to produce a more accurate, robust result. They handle noisy data well, and they allow you to analyse feature importance and understand which inputs are driving the predictions. This is critical in cement, where understanding why a model recommends something is often as important as the recommendation itself.
Neural networks can approximate any function, but they need large amounts of data and are prone to overfitting. They’re also a black box – hard to explain, harder to audit. Used well, they unlock a level of predictive power that’s hard to reach with traditional methods. Modelling volatiles and other gases is a good example. But that power comes with complexity. Sometimes a simpler, more easily explained model does the job.
Transformers are essentially very large, complex neural networks the most well known being LLMs (large language models) like ChatGPT which are trained on text. The architecture is genuinely impressive, but it’s solving a different problem than process optimisation.
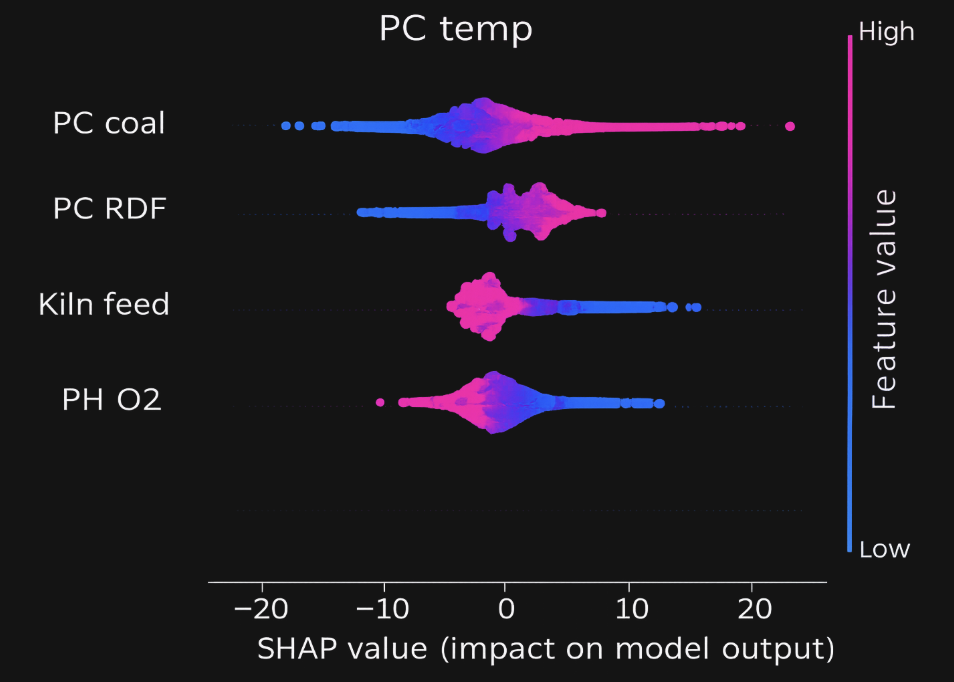
This is where explainability becomes an important part of how AI solutions are built and used. To effectively evaluate why a model predicted a certain value, techniques like Shapley values (SHAP) can help. SHAP determines how much each input feature contributed to a specific prediction by measuring how much adding or removing that feature changes the result.
For example, if your model predicts precalciner temperature, SHAP can tell you: “Coal throughput contributed +15°C, RDF contributed -8°C, and the previous temperature reading contributed +3°C.” SHAP are just one example. That level of transparency builds trust and it’s essential when you’re handing control decisions over to an automated system.
5. The ML tools already running in plants – and what they’re actually doing
Machine learning isn’t future technology. It’s running in cement plants across the world today. Understanding the mechanism means you can evaluate whether it’s working.
Soft sensors
A soft sensor is a machine learning model that acts as a virtual sensor to simulate an installed sensor or sample measurement. For example clinker quality soft sensors, like free lime, can generate predictions every 15 minutes instead of waiting 2 hours for a lab sample.
A soft sensor on it’s own helpful information but the real value in a soft sensor comes from integrating it with an optimiser. This matters because it enables earlier control actions. Instead of reacting to a lab result that describes what happened two hours ago, you can adjust setpoints now, before the process drifts too far.
Digital twins
A digital twin is a machine learning model that simulates the process. It forecasts what will happen in the near future (typically 15 minutes to an hour) under different setpoint scenarios.
For example: if you increase calciner RDF by 0.5 tph and decrease kiln coal by 0.3 tph, what happens to precalciner temperature, CO levels, and TSR? The digital twin runs those simulations so you can evaluate the trade-offs before taking action.
Optimisers
Optimisers are machine learning models that take a control action in the plant to optimise the process. They combine three things:
- An objective function that you configure, which tells the system what to prioritise
- A digital twin that simulates the process and the impact of possible control actions
- A controller that takes the best control action in your plant.
The objective function is where your plant’s priorities come in. You might be balancing:
- Maximising thermal substitution rate (TSR)
- Reducing fuel cost
- Staying within CO and NOₓ limits
- Maintaining stable precalciner temperature
- Preventing blockages by keeping volatiles in check
- Hitting throughput targets
The optimiser tests every possible setpoint adjustment, evaluates how each one performs against your objective function, and chooses the best action. Then it sets the setpoints automatically in closed-loop control.
Instead of a dashboard recommending actions, the optimiser adjusts the plant in real time, maintaining stability and freeing your team to focus on higher-order tasks.
Final thoughts
Technical literacy is not about becoming a machine learning engineer. It’s about having enough grounding to ask the right questions, spot the red flags in supplier pitches, and make decisions you can defend.
The gap between those talking about using AI and those deploying it for real value is widening. But the foundation is simple: understand what tools can and can’t do and what’s going to work in your world, so you can evaluate offerings and insist that any solution can explain why it’s making the decisions it makes.