
We might not be the first to posit that engineering culture in a tech startup is crucial to a company’s success and the satisfaction and growth of its engineers, but we certainly believe it. In this blog, two of our engineers, Chiara and Enrico, share their favourite aspects of the engineering culture at Carbon Re.
A strong culture enables elite engineering
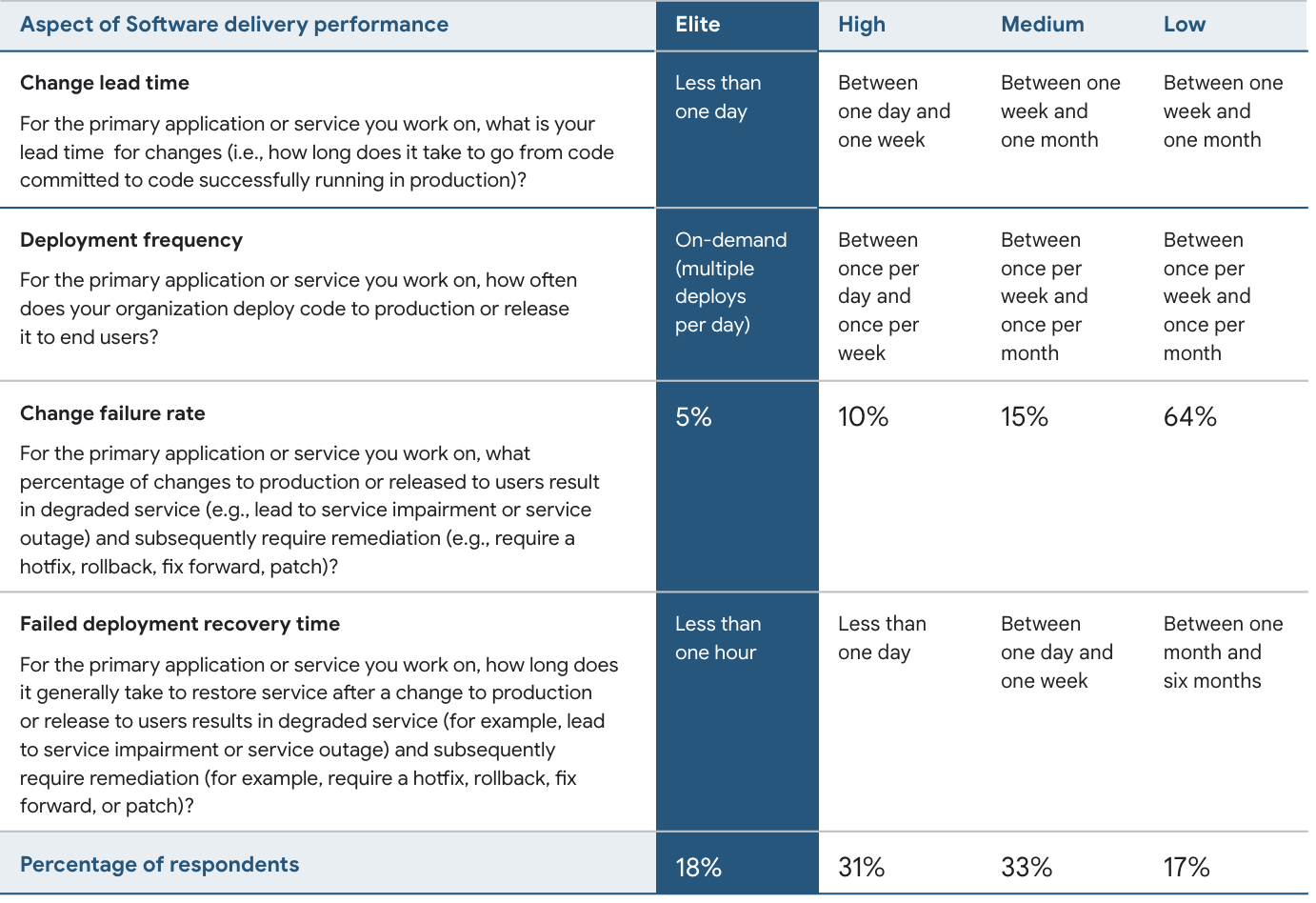
During our time here, the engineering team has:
- built a streaming data pipeline, processing IoT data delivered via MQTT with seconds of latency, using highly-reliable AWS serverless services.
- iterated quickly on a product that is currently driving reductions in the CO2 emissions of cement plants
- deployed an average of 10 times per day thanks to a strong and fast CI/CD pipeline with plenty of quality gates and automatic deployments to pre-prod and prod environments.
- seen a Failure Rate of 3% per month, with a 56 mins Mean Time to Restore, thanks to the CI/CD pipeline speed, and extensive observability of the prod environments
…which sets us at elite Engineering level according to the Google DORA framework! We have no doubt, our strong engineering culture was key in enabling us to achieve this.
Engineering and Product work tightly together
By far one of the main reasons we love working at Carbon Re is the absence of silos across the Engineering and Product teams. The teams work closely together, so new feature requests and projects never feel like they’ve come out of thin air. Having small teams makes it easy to build good relationships with everyone (the two of us currently sit within a 2 meter radius from all members of the product team). It makes it a pleasure to work together and helps to achieve a tight feedback cycle: it’s always quick and easy to ask for clarification or propose a change. This has three key consequences:
- As engineers, we feel completely embedded in the development of the product. We truly feel that we’re part of a team who are building something great, and that we’re not just code machines
- When we start working on a ticket, it’s clear to us why it’s important and the impact it will have on our customers
- It’s not a one way street from Product to Engineering: the product team are incredibly receptive to feedback, and will consider and reasonably prioritise requests coming from the engineering team
Fast development cycle
We are here to solve hard, important problems, and to do so with urgency. We work closely with our customers and want to build and maintain their trust, while also iterating quickly on our product.
To achieve this, we can’t waste time on slow deployment processes or long, manual testing. We have invested into developing a strong CI/CD pipeline to run our automated tests and deployments. We practice Test Driven Development and strive to quickly and iteratively ship small, well-tested changes to production. This helps to surface issues early, makes it generally easy to revert a change if needed, and takes the fear out of deploying.
All of this allows us to effortlessly deploy to production multiple times a day. As soon as we finish working on a change, we get to see the impact on our customers almost immediately. It is delightful.
Obsessed with observability
Inevitably, sometimes things will find their way through the cracks, and issues will arise. We understand that. Our response is to obsess over the observability of our software.
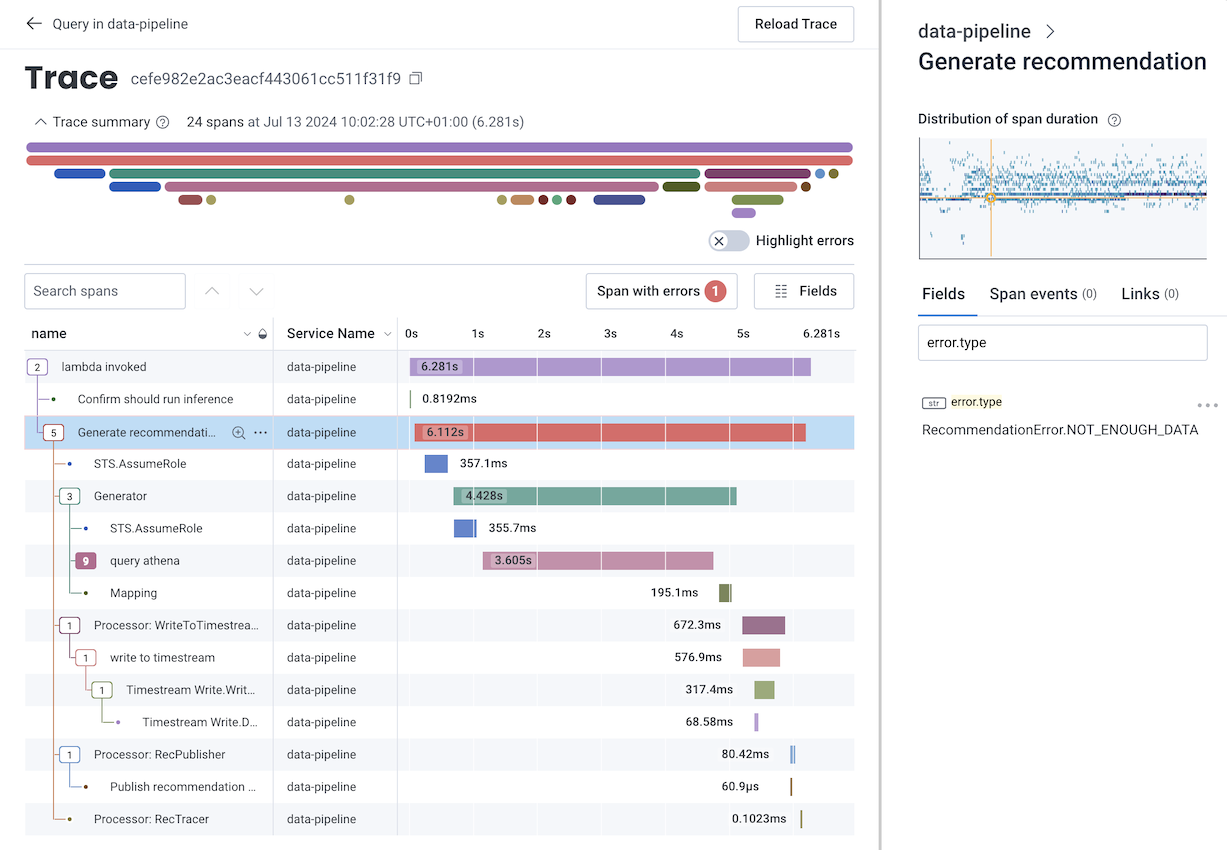
We use Honeycomb as our observability platform and we maintain dashboards to monitor all parts of our system. When something goes wrong, we receive an alert which typically points us to a specific dashboard. The dashboard allows us to drill down into the details: did that database query take longer than usual? How much data did we process? Why didn’t our model run for that particular timestamp? We are getting better and better at knowing what information is valuable for us to track, so typically with a few clicks we can spot the root cause of the problem. We can then replicate the failure and work on a fix.
We hate alert fatigue: when an alarm is triggered, we either fix the problem, or – if it was a false alarm – we treat fixing the alarm itself as a matter of priority.
Good observability also makes it easier to identify where the bottlenecks in our system are: we can see which processes are using the most resources or taking the most time, which helps us drive decisions on what to optimise next.
No-blame culture
Developing software inevitably means occasionally breaking it. From the newest startups to the most powerful tech giants, software teams are constantly breaking and un-breaking their systems.
We adopt a strict no-blame culture. When we have an incident, we don’t point fingers, instead we jump in to figure out the issue and fix it. We then always have a post-mortem to reprocess events, identify the weaknesses in our processes that allowed things to happen, and schedule work to ensure the same issue can’t happen again.
The combination of a solid CI/CD pipeline, good observability and no-blame culture mean that we are confident in doing our work, as we know that on the off chance something will happen:
- we’ll be supported in fixing it
- we have the tools to debug the problem quickly
- once we find a fix, we can ship it to production quickly
- the whole process will eventually result in the whole system becoming more robust than it was before
So is it all perfect?
Unsurprisingly, no. There are several challenges that come from being a small team in a fast moving startup.
As we want to be continuously improving our product to reduce the carbon footprint of cement plants, we need to be ready to try many things, keep what works, and change or drop what doesn’t. Sometimes we’ll work hard on something, only to then realise we need to change approach. This process of constant change and adaptation is intrinsic to life in a startup, and while we thrive on it, it can at times get tiring.
As a small dynamic team where everyone wears several hats, there will also inevitably be days involving a good amount of context switching, which can be draining. Thankfully, we are mindful of this, and know that we can sound the alarm if it becomes excessive.
For us, these drawbacks are well worth the satisfaction of working on a high-impact product, in a team with great engineering culture.
Carbon Re is a fast-paced, quality, and mission-driven environment full of people who are passionate about having an impact in an industry that is responsible for 8% of global carbon emissions. We are proud to work with best practices and cutting-edge technologies, and we champion innovation and experimentation. As one of the few companies running ML models in an applied industrial context, we are always looking for like-minded people. If all or most of this resonates with you, come talk to us! 🙂

Machine Learning Engineer & Software Engineer